Chapter 3 Data
3.1 Sources
As stated in Chapter Proposal, we have three major data sources:
- Metacritic, for critic reviews
- Rate Your Music (RYM), for user ratings
- Spotify, for album streams/popularity
We first scrapped album ratings from Metacritic, a famous and reliable website that aggregates reviews and ratings for music albums. We scrapped the critic ratings for albums released between 2018 and 2022(inclusive) and concatenate them to one table. We get 2275 records in total. (Please see metacritic.Rmd for scraping and cleaning code)
Based on the albums and artist name we got from the Metacritic website, we collected the user rating of corresponding albums from Rate Your Music (RYM), which is the largest community-driven online music database. To be specific, we query each albums by its name and artist through a modified unofficial API rymscraper. (Please see rym.ipynb for querying and cleaning code)
For the user popularity of each album, we collect popularity from Spotify official APIs. Since Spotify provides the popularity of each track in an album, we records the min, mean, median, and max popularity of all tracks in a album for each album. (Please see spotify.Rmd for querying and cleaning code)
Additionally, from Spotify APIs, we also collect the features of all songs that appears in the album that we collected before. That is, we have a new table to save the duration, name, popularity, acousticness, danceability, energy, instrumentalness, key, liveness, loudness, mode, speechiness, tempo, time_signature and valence of each song/track.(Please see spotify_tracks.Rmd for querying and cleaning code)
Because the raw data is not so clean and showing them directly would be a disaster, we prefer introduce the types of variables and other information of these data set during&after cleaning and transformation. :)
3.1.1 Data collecting
Since data collecting and processing is especially important in our project, before moving on to the cleaning and transformation section, we would like to further explain the method and logic behind our data collecting.
First, none of our data is from an existent file; we have to scrape the data manually or use some APIs. And for every source, there are two ways to get the data:
- Scrape a chart. All sources provide some chart webpages, e.g.,https://rateyourmusic.com/charts/. These charts are in a table HTML element, so we can easily scrape them to get a CSV file.
- Search a database. There are existent official/unofficial APIs, or we can build some basic APIs, for all sources. These APIs enable us to get the information of an album through related information, like artist and album name.
Therefore, the first question is which way should we use to collect the data. There are also two approaches:
- Get all data by scrapping charts. Then join the charts from different sources.
- Get a base chart, then search the databases for every record in the base chart.
We adapted the second approach, because the join operations may lead to either too many missing values (outer join) or too few records (inner join). Also, Spotify doesn’t provide enough charts data. Therefore, we scrapped Metacritic charts as the base charts, and then search the records in the charts using RYM and Spotify APIs.
The Spotify APIs performed relatively well and are closed source, hence we we didn’t touch them. However, the RYM unofficial APIs miss many values without modification. Therefore, we enhance the RYM APIs by a three-layer search:
- First we transform the artist and album name to an URL, and search the album directly using the URL. Since an artist or an album may have many alternative names and may contain special characters, this search may return an empty result with a high probability.
- If the first search fails, we then use the artist name to search their discography. Then we look through the discography and return the closest match to what we are looking for. This search almost always find the album except for some edge cases like it finds the wrong artist.
- If the first two searches fail, we then directly search the database using string “artist - album”. Among returned records, we get the closest match to what we are looking for. Since a search engine will always return some results even the database doesn’t contain the record, this search hardly fails.
The original RYM APIs only perform the second-layer search. Also, we adjust the “get closest match” method to make it more tolerant to special characters. Although this three-layer search almost found all albums, some of the results are wrong; we will explain the reasons in section Missing value analysis.
3.2 Cleaning / transformation
3.2.1 Metacritic Data
As we can see from below, the raw data we scrapped from the Metacritic, it is not so clean. The data doesn’t have proper column name and some columns are useless in the following analysis. And more importantly, the data type of all columns are characters.

Thus, before analyzing, we did data cleaning to the Metacritic data set:
- Delete useless columns: V6, V8, V9 are useless because of either containing duplicate data or having long text that is not helpful.
- Rename left columns: according to the meaning of each row, we rename the columns as
Metacritic_Score,Rank,Album_Name,Singer,Release_Date,Description,User_Score,Release_Year - Transform the data
- Metacritic_Score & Rank: transform them from type char to type int for future analysis.
- Singer: contains redundant characters “by”, e.g. “by Fiona Apple”. Extract only the artist name, e.g. “Fiona Apple”
- User_Score: transform is from type char to type float for future analysis.
- Release_Date: it is originally in char type, e.g. “April 17, 2020”. Transform it to R datetime type, e.g. 2020-04-17
- id: for future usage(joining different dataframe)
After transformation and cleaning, the Metacritic data contains 2275 observations of 9 different variables.
| Variable Name | Data Type | Meaning |
|---|---|---|
| id | int | album id |
| Metacritic_Score | int | critic rating on Metacritic |
| Rank | int | rank in release year |
| Album_Name | chr | album name |
| Singer | chr | album artist |
| Release_Date | Datetime | album release date |
| Description | chr | album description |
| User_Score | num | album user score |
| Release_Year | int | album release year |
3.2.2 Rate Your Music
As we can see from the snapshot of the description of sample album of the raw data we collected from Rate Your Music (RYM), the data is messy.

Before conducting merging, data need cleaning and transformation.
- Delete useless columns: Type, Recorded are useless because they contain duplicate data.
- New column: We found that
RYM Ratingis in charcter type and contains not only ratings but also number of people who rate the album. Therefore, we extract the number of ratings and create a new column namedNum_of_RYM_Ratings - Transform the data
- Released: it is originally in char type, e.g. “14 September 2018”. Transform it to R datetime type, e.g. 2018-09-14
- RYM Rating: Extract ratings from characters and change the data type to numerate.
- id: for future usage(joining different dataframe)
- reserve the left data and transform them in the future if needed.
After transformation and cleaning, the RYM data contains 2275 observations of 13 different variables.
| Variable Name | Data Type | Meaning |
|---|---|---|
| id | int | album id |
| RYM.Rating | int | user rating on RYM |
| Ranked | chr | rank in release year |
| Name | chr | album name |
| Artist | chr | album artist |
| Released | Datetime | album release date |
| Descriptors | chr | album description |
| Track.listing | chr | tracks in album |
| Release_Year | int | album release year |
| Genres | chr | album genre |
| Language | chr | song language |
| Colorscheme | chr | album colorscheme |
| Num_of_RYM_Ratings | int | number of users who rate the album |
3.2.3 Spotify
The data we get from Spotify official APIs is quite clean. Thus we will directly introduce the variables.
The album data set contains 2275 observations of 6 different variables.
| Variable Name | Data Type | Meaning |
|---|---|---|
| id | int | album id |
| avg_pop | num | average popularity of all tracks in this album |
| max_pop | int | max popularity among all tracks in this album |
| min_pop | int | min popularity among all tracks in this album |
| med_pop | num | median popularity of all tracks in this album |
| n | int | number od tracks in this album |
The data set for tracks contains 26834 observations of 16 different variables.
| Variable Name | Data Type | Meaning |
|---|---|---|
| id | int | album id |
| track_id | chr | id for tracking |
| duration_ms | int | duration of each song in ms |
| name | chr | name of song |
| popularity | int | popularity |
| acousticness | int | acousticness |
| danceability | num | danceability |
| energy | num | energy |
| instrumentalness | num | instrumentalness |
| key | int | key |
| liveness | num | liveness |
| loudness | num | loudness |
| mode | int | mode |
| speechiness | num | speechiness |
| tempo | num | tempo |
| time_signature | int | time_signature |
| valence | num | valence |
3.2.4 Final Data Set
After cleaning data set from each website/API, we concatenate 3 album-level data set by id, which was generated during the query to API using function tibble::rowid_to_column.
The final album data set has 2275 observations of 20 variables.(For duplicate columns, we only conserve 1 column in the final data set)
The following picture is for a rough look. Please see this for a detailed look.

Remember that we also have a track-level data set from Spotify. We will have exploratory data analysis based on it later.
3.3 Missing value analysis
We first analyze the missing value patterns of the joint album-level data.
## NOTE: The following pairs of variables appear to have the same missingness pattern.
## Please verify whether they are in fact logically distinct variables.
## [,1] [,2]
## [1,] "RYM_Rating" "Num_of_RYM_Ratings"
## [2,] "Tracks" "Colorscheme"
## [3,] "avg_pop" "max_pop"
## [4,] "avg_pop" "min_pop"
## [5,] "avg_pop" "med_pop"
## [6,] "avg_pop" "n"
## [7,] "max_pop" "min_pop"
## [8,] "max_pop" "med_pop"
## [9,] "max_pop" "n"
## [10,] "min_pop" "med_pop"
## [11,] "min_pop" "n"
## [12,] "med_pop" "n"## [1] id Metacritic_Score Rank Album_Name
## [5] Singer Release_Date Desciption Release_Year
## [9] RYM_Rating Genres Language Tracks
## [13] Colorscheme RYM_Rank Num_of_RYM_Ratings avg_pop
## [17] max_pop min_pop med_pop n
## <0 rows> (or 0-length row.names)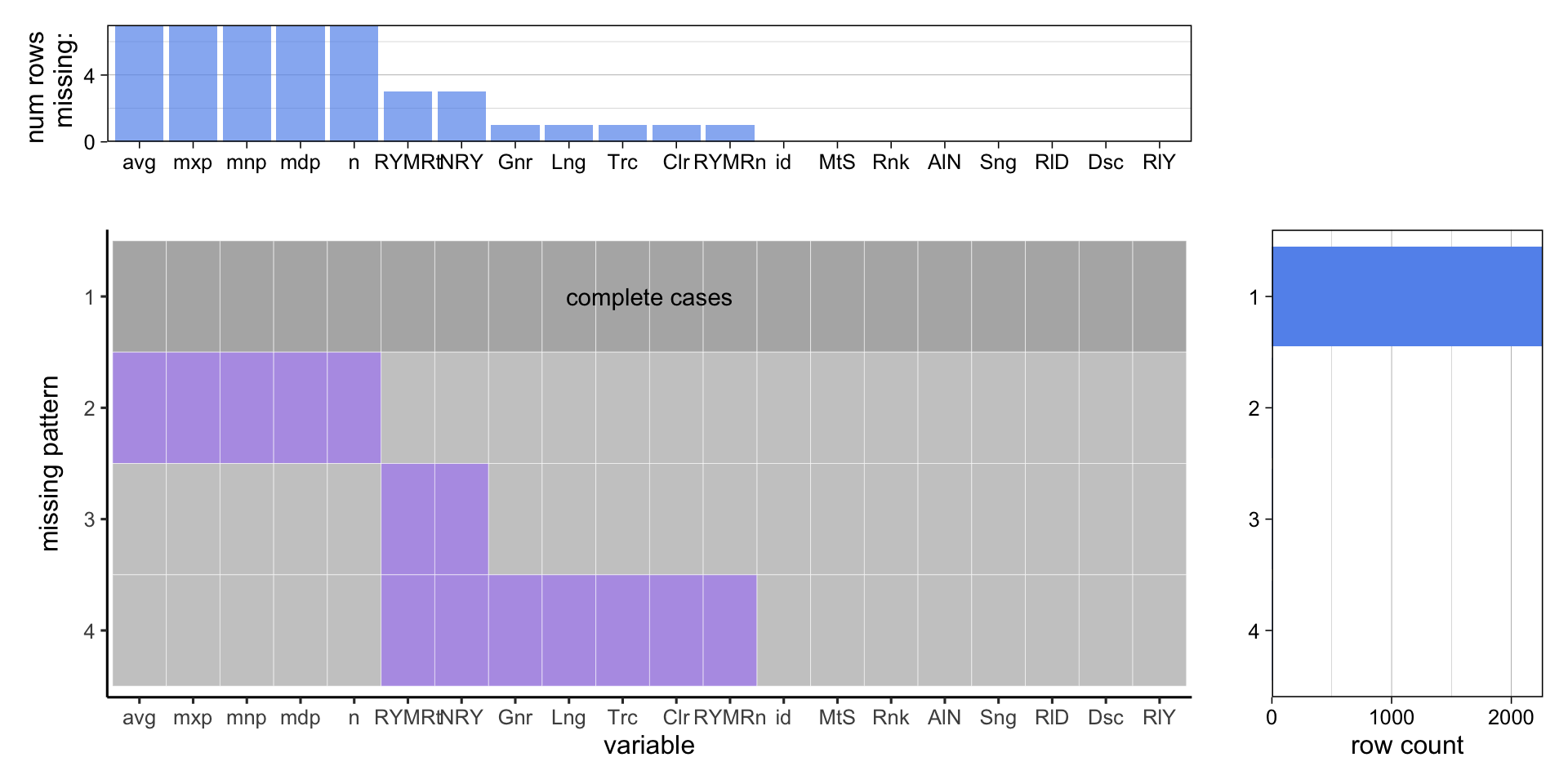
As we can see, there are only few values missing. This is due to the “search” nature of our collecting method. We get the matched results from some search engines; since it is rare for search engines to return an empty list, and we relax the matching criteria, values are rarely missing.
Also, the missing patterns are very clear:
- If we cannot find an album on Spotify, then the data on its tracks are all missing; this includes
avg_pop, max_pop, min_pop, med_pop, n.- The missing albums on spotify are due to copyrights restrictions. For example, the band Belly removed their album “Dove” from Spotify. All of these albums can be searched on Spotify, but no tracks information are offered.
- If an album gets no ratings on RYM, its
RYM_RatingandNum_of_RYM_Ratingsare both missing.- There are two albums we found on RYM but with no
RYM_RatingandNum_of_RYM_Ratings:- “Get Up Sequences, Pt. 1” by The Go! Team. On RYM, the title of this album is “Get Up Sequences Part One”, and the artist has another album called “Get Up Sequences Part Two” comming up. Since our algorithm doesn’t know “1” is “One”, it returned the wrong, unreleased album, which has no ratings.
- “MOSS” by Maya Hawke. This is an internal error of RYM: the page of “MOSS” https://rateyourmusic.com/release/album/maya-hawke/moss leads to a wrong page which has no rating
- There are two albums we found on RYM but with no
- If we cannot find an album on RYM, then the data offered by RYM is missing; this includes
RYM_Rating, Num_of_RYM_Ratings, Genres, Language, Tracks, Colorscheme, RYM_Rank.- There is only one album we cannot find on RYM: “Pulse/Quartet” by Steve Reich.
However, complete data doesn’t mean correct data. There is no such thing as a free lunch. The completeness of our data provided by the “search” nature of our data collecting method also raise the probability of returning a wrong data, when the data should be missing.
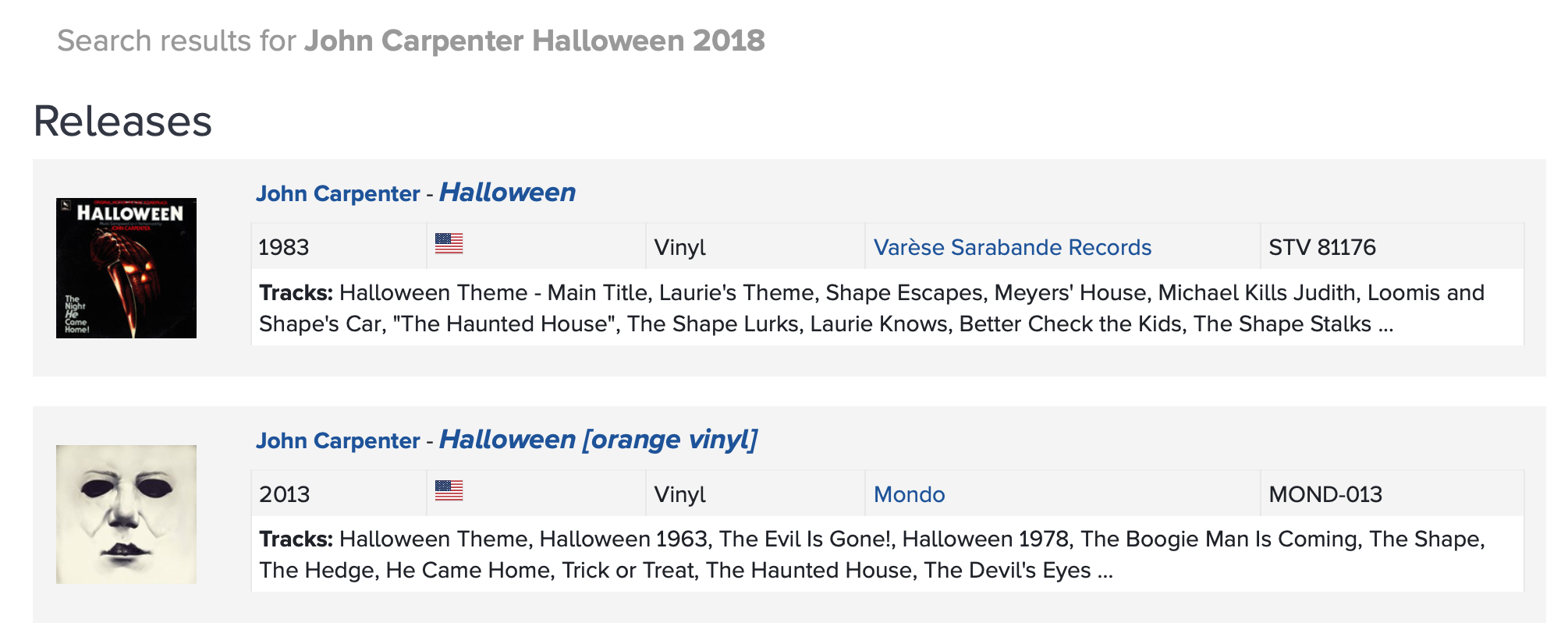
For example, we use the first album returned by the Spotify search API as our observation. However, if the album doesn’t exist on Spotify, it may still return some related results. Then we collect the wrong data. Such senarios are more often when using RYM API. For example, “Halloween [Original 2018 Motion Picture Soundtrack]” by John Carpenter in the Metacritic chart is a 2018 soundtrack which is not included by RYM. However, this album has many older versions, so the RYM API returns an older version which is released in 1983. Some other examples includes that the album in the Metacritic chart is a new live version which is not included by RYM, so the RYM API returns the studio version.
Also, we are exploring the “art” world; artists are full of creative ideas to name themself and their albums. Therefore, there are relatively more edge cases where we will get the wrongly-matched data.
However, it is hard to consider all the edge cases and eliminate the wrong data. It is our next steps to reduce the error possibility.
Now we give a brief analysis of the missing values in the track-level data.
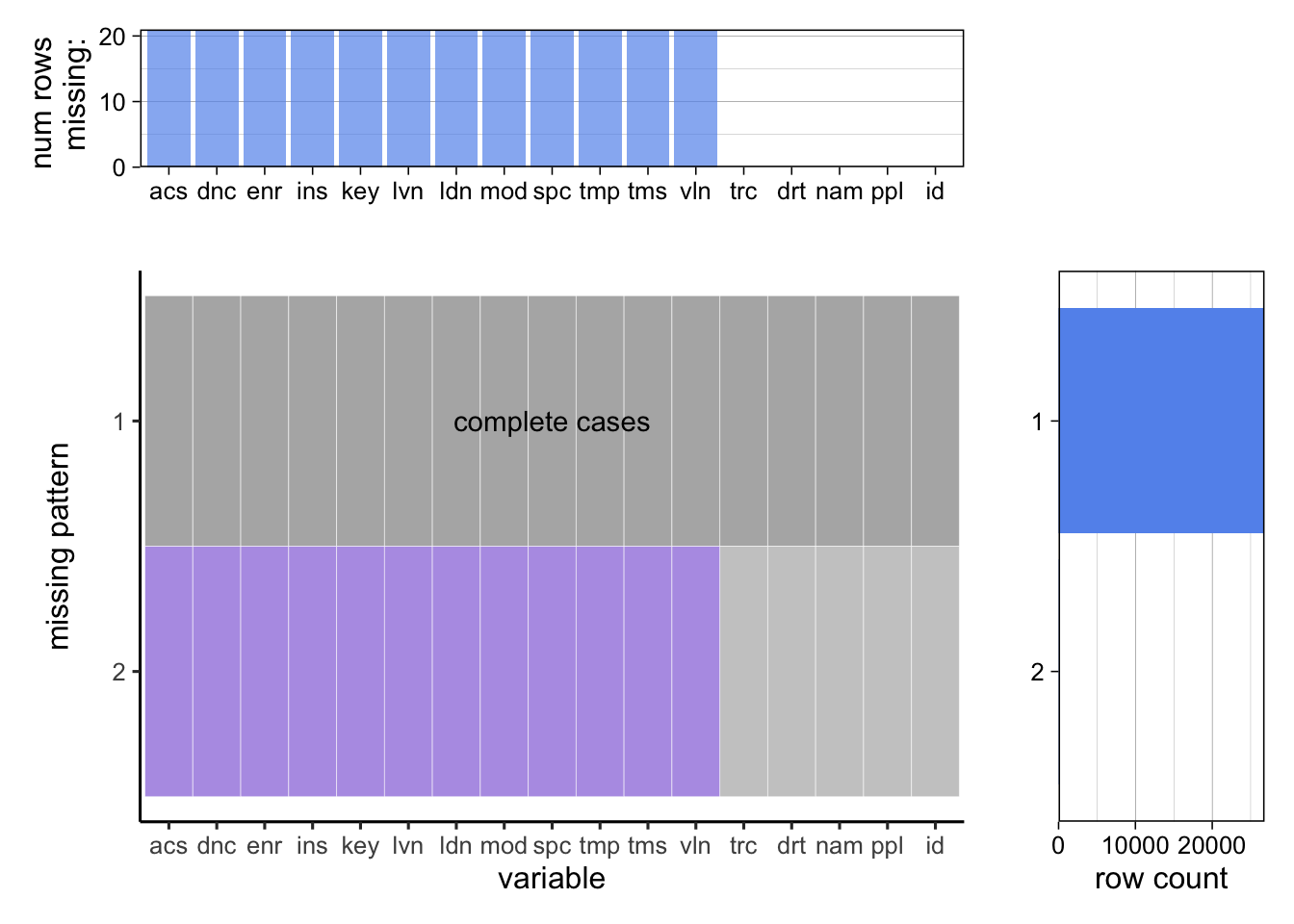
As we can see, since we are collecting the tracks information of our already collected albums, the basic information like name (nam) and popularity (ppl) has no missing values. However, there are 20 tracks that do not have audio features. And we can see that if one of the audio feature is missing, all other audio features of that track are also missing. Therefore, we can deduce that Spotify may not record the audio information for those tracks, or the APIs fail to get the audio features.